


ENTERPRISE GRADE AI TRUST
AI-Powered
Audio Moderation
Shield your brand from AI-driven harmful outputs. Deepcleer's comprehensive evaluation and monitoring tools ensure every AI interaction aligns with your corporate values and global regulations.
Support the Various Risky Content Detection
Exhaustive coverage across seven core linguistic risk categories using hyper-specific detection vectors.
Sexual
Flag explicit dialogue, erotic audio, and vulgarity. Detect suggestive breathing, moaning, and illicit rhythmic chanting (Hanmai) through acoustic analysis.
Prohibited Goods
Real-time identification of audio promoting narcotics, gambling, contraband, and unauthorized transactions.
Hate Speech
Recognize harassment, slander, and toxic behaviors to safeguar user well-being.
Spam
Detect unauthorized audio advertisements and attempts to divert users via external contact information.
Support Audio Recognition in Multiple Scenarios
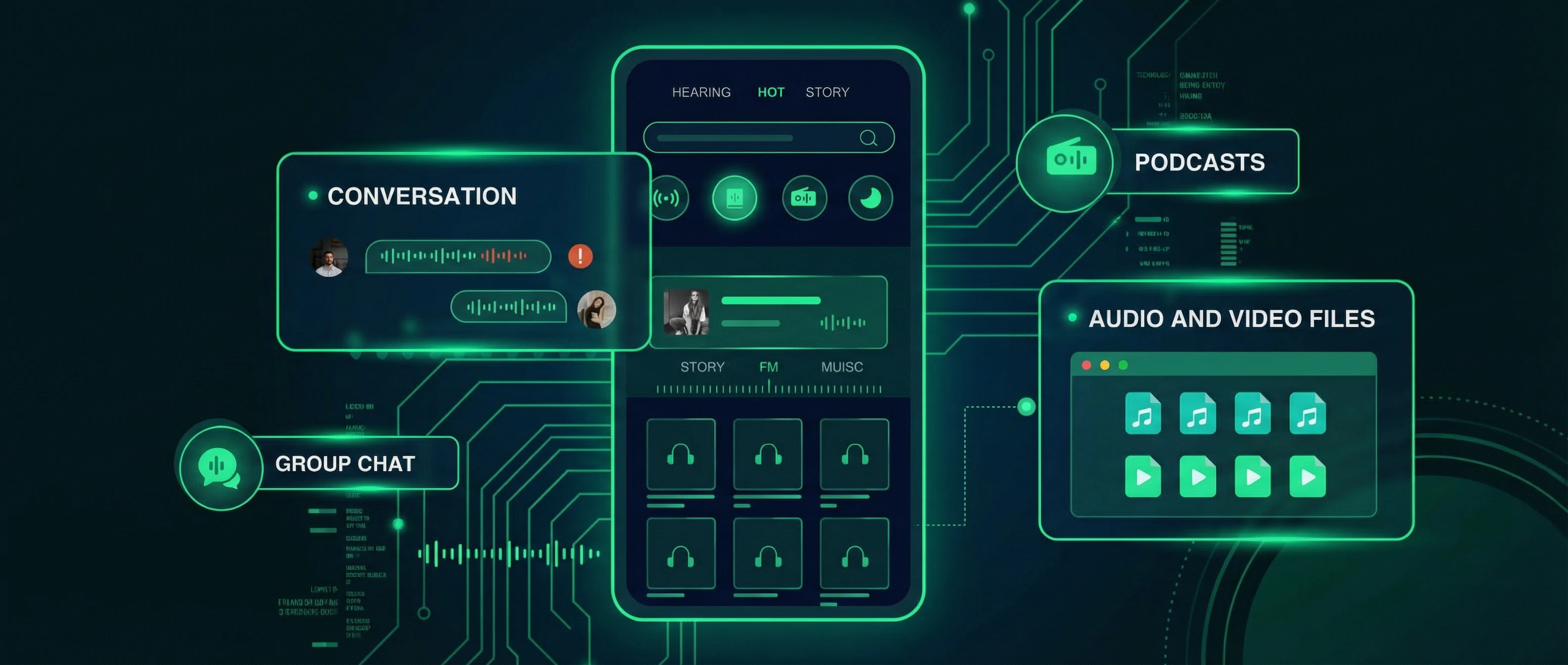
Core Features
Multi-Layered Hybrid Model Fusion
To eliminate the inherent limitations of single-algorithm systems, we integrate a diverse stack of advanced architectures, including GAN (Generative Adversarial Networks), TDNN (Time Delay Neural Networks), LSTM, and RNN. This high-efficiency ensemble framework ensures ultra-high precision and robust performance in the most complex acoustic environments.


Internationalized Cross-Lingual Detection
Built for your global expansion. Our engine features native support for a vast array of international languages, enabling precise identification of risks delivered in English and other major global languages. Whether it's localized slang or cross-border interactions, our system keeps your global GTM strategyang or cross-border interactions, our system ensuresyour global GTM strategy remains compliant and secure.
Holistic Analysis of Verbal& Non-Verbal Cues
We go beyond simple speech-to-text (ASR). Our engine provides 360° coverage by recognizing non-verbal risks such as suggestive moaning, erotic breathing, and other acoustic violations. Furthermore, we offer advanced Voiceprint Recognition and Timbre Analysis, allowing you to identify recurring offenders and manage user identities at a biometric level.

Detection Technology that Makes the Recognition Result More Accurate

Why DeepCleer?
Granular & Industry-Tailored Taxonomy
Sophisticated hierarchy of 1,000+ third-levelcontent tags deeply optimized for diverse industry scenarios.
Account-Level Intelligence
We go beyond content pieces by correlating multi-dimensional user behaviors for proactive platform protection.
Global-Scale Elasticity
Second-level elastic scaling ensuring zero-latency protection across our global multi-cluster architecture.
Agile Intelligence & Rapid Iteration
Stay ahead with real-time sentiment tracking and case-driven optimization of our incremental models.